聚水潭数据集成到MySQL的技术案例分享
在现代企业的数据管理中,如何高效、可靠地实现不同系统之间的数据对接是一个重要的技术挑战。本篇文章将聚焦于一个具体的系统对接集成案例:将聚水潭的仓库信息集成到MySQL数据库中。通过这一案例,我们将探讨如何利用轻易云数据集成平台,实现高吞吐量的数据写入、实时监控和异常处理等关键技术。
在本次方案中,我们的目标是将聚水潭平台上的仓库信息,通过API接口/open/wms/partner/query定时抓取,并批量写入到MySQL数据库中的BI崛起-仓库信息表_copy。这一过程中,涉及到多个关键技术点,包括但不限于:
- 高吞吐量的数据写入能力:确保大量数据能够快速被集成到MySQL数据库中,提升数据处理的时效性。
- 集中监控和告警系统:实时跟踪数据集成任务的状态和性能,及时发现并处理潜在问题。
- 自定义数据转换逻辑:适应特定业务需求和数据结构,实现灵活的数据映射。
- 分页与限流处理:有效应对聚水潭API接口的分页和限流问题,确保数据完整性和稳定性。
- 异常处理与错误重试机制:针对可能出现的数据对接异常情况,设计可靠的错误重试机制,提高系统鲁棒性。
通过这些技术手段,我们不仅能够确保从聚水潭获取的数据不漏单,还能实现大规模数据快速写入到MySQL。同时,通过实时监控与日志记录功能,可以全面掌握整个数据处理过程,从而提高业务透明度和效率。
接下来,我们将详细介绍这一集成方案的具体实施步骤及其背后的技术原理。
调用聚水潭接口获取并加工数据
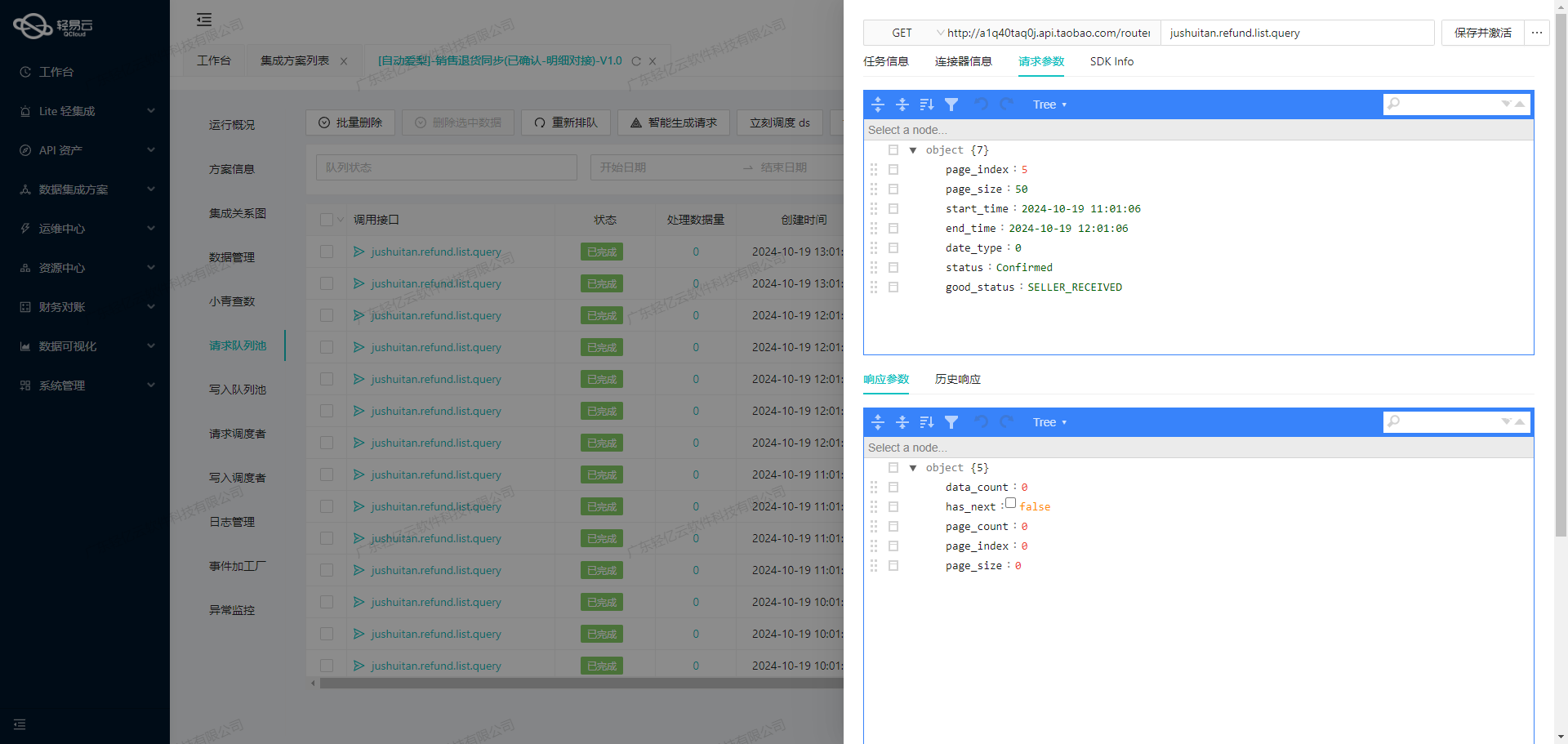
在轻易云数据集成平台的生命周期中,调用源系统接口是至关重要的一步。本文将详细探讨如何通过调用聚水潭接口/open/wms/partner/query来获取仓库信息,并进行必要的数据加工处理。
聚水潭接口配置与调用
首先,我们需要了解聚水潭接口的基本配置和调用方法。根据提供的元数据配置,聚水潭接口采用POST方法进行请求,主要参数包括分页索引(page_index)和每页条数(page_size)。
{
"api": "/open/wms/partner/query",
"effect": "QUERY",
"method": "POST",
"number": "name",
"id": "wms_co_id",
"name": "name",
"idCheck": true,
"request": [
{
"field": "page_index",
"label": "每页条数",
"type": "string",
"describe": "每页多少条,非必填项,默认30条",
"value":"{PAGINATION_START_PAGE}"
},
{
"field":"page_size",
"label":"页码",
"type":"string",
"describe":"第几页,非必填项,默认第一页","value":"{PAGINATION_PAGE_SIZE}"
}
],
“autoFillResponse”: true
}数据请求与清洗
在实际操作中,为了确保数据完整性和准确性,需要处理分页和限流问题。通常情况下,我们会设置合理的分页参数,以避免一次性请求过多数据导致超时或失败。
- 分页处理:通过循环机制逐页请求数据,每次请求完成后检查返回结果是否为空,如果为空则停止继续请求。
- 限流控制:为了防止频繁调用导致API限流,可以设置适当的延迟时间或者使用批量请求策略。
以下是一个简化的伪代码示例:
def fetch_data_from_api():
page_index = 1
page_size = 30
while True:
response = call_api(page_index, page_size)
if not response or len(response) == 0:
break
process_data(response)
page_index += 1
def call_api(page_index, page_size):
# 调用聚水潭API并返回结果
pass
def process_data(data):
# 数据清洗与转换逻辑
pass数据转换与写入
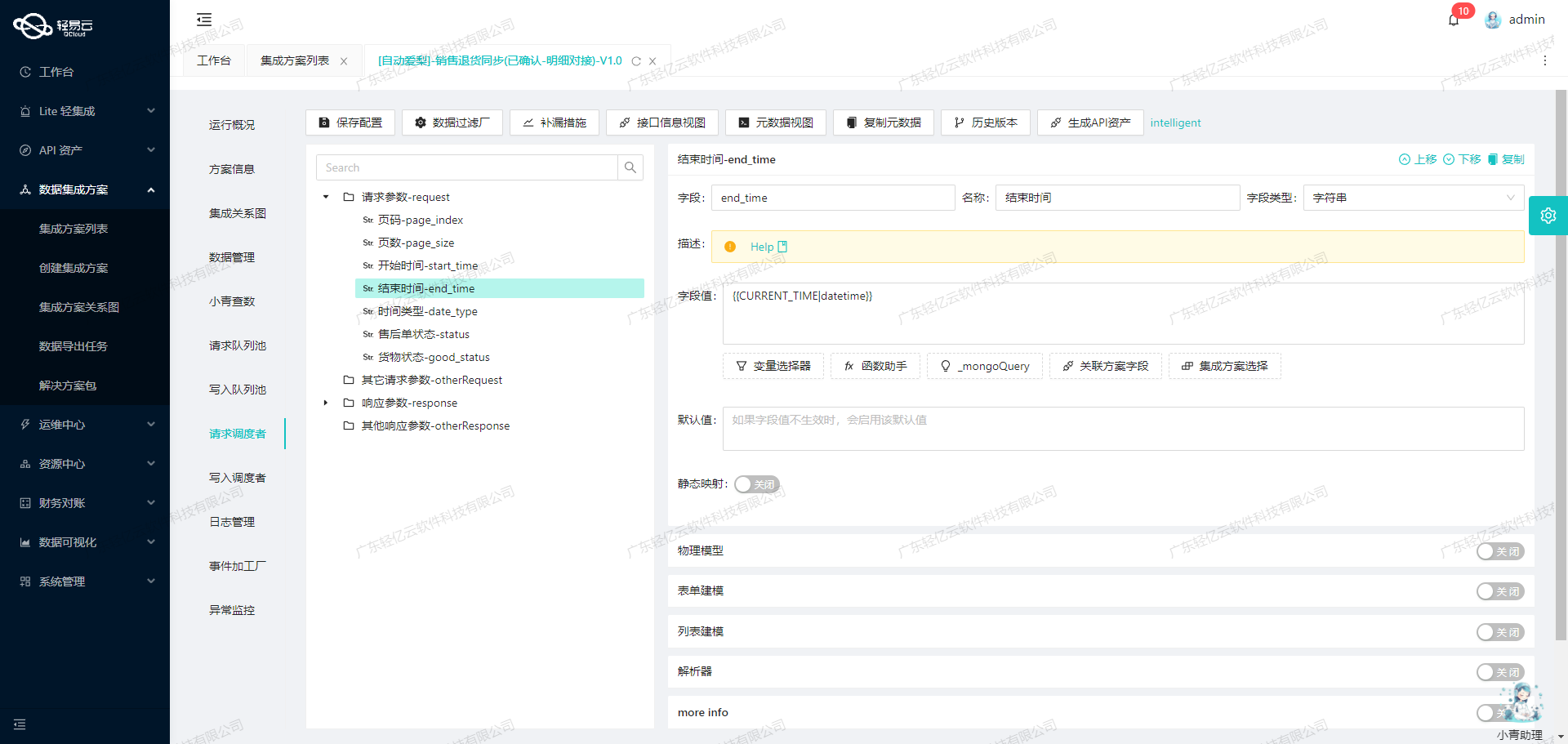
在获取到原始数据后,需要对其进行清洗和转换,以适应目标系统的数据结构。例如,将字段名称映射为目标数据库中的字段名称,对日期格式进行标准化等。
- 字段映射:根据元数据配置,将源系统中的字段名映射为目标系统中的字段名。
- 格式转换:对日期、数字等特殊格式的数据进行标准化处理。
- 异常处理:对于缺失值、非法值等异常情况进行检测和修正。
def process_data(data):
cleaned_data = []
for record in data:
cleaned_record = {
'warehouse_id': record['wms_co_id'],
'warehouse_name': record['name']
}
cleaned_data.append(cleaned_record)
write_to_target_system(cleaned_data)
def write_to_target_system(data):
# 将清洗后的数据写入目标系统,例如MySQL数据库
pass实时监控与日志记录
为了确保整个数据集成过程的透明度和可靠性,可以利用轻易云平台提供的集中监控和告警系统,对每个步骤进行实时监控,并记录详细日志。一旦出现异常情况,可以及时发现并采取相应措施。
- 实时监控:通过可视化工具实时跟踪数据流动状态,包括成功率、失败率、响应时间等关键指标。
- 日志记录:详细记录每次API调用及其响应结果,包括成功与否、错误信息等,为后续排查问题提供依据。
综上所述,通过合理配置聚水潭接口参数、有效处理分页与限流问题,以及对获取的数据进行清洗转换,可以实现高效稳定的数据集成。同时,通过实时监控和日志记录机制,进一步提升了整个过程的透明度和可靠性。
数据请求与清洗
在数据集成的第二步中,我们重点关注将已经集成的源平台数据进行ETL转换,并最终写入目标平台 MySQLAPI 接口。为了实现这一目标,首先需要从聚水潭系统中请求并清洗数据。
定时可靠的抓取聚水潭接口数据
通过调用聚水潭接口 /open/wms/partner/query,我们可以定时抓取仓库信息数据。为了确保数据完整性和准确性,需要处理分页和限流问题。使用异步任务调度系统,可以有效地管理请求频率,避免触发接口限流机制。
数据转换与写入
自定义数据转换逻辑
在轻易云数据集成平台中,我们可以自定义数据转换逻辑,以适应特定的业务需求和数据结构。以下是元数据配置中的关键部分:
{
"field": "main_params",
"label": "主参数",
"type": "object",
"describe": "对应主语句内的动态参数",
"children": [
{"field": "name", "label": "分仓名称", "type": "string", "value": "{name}"},
{"field": "co_id", "label": "主仓公司编号", "type": "string", "value": "{co_id}"},
{"field": "wms_co_id", "label": "分仓编号", "type": "string", "value": "{wms_co_id}"},
{"field": "is_main",
"label": "是否为主仓,true=主仓",
"type": "string",
"value":"_function CASE '{is_main}' WHEN ' ' THEN 'false' ELSE 'true'END"},
{"field": "status",
"label":"状态",
"type":"string",
"value":"{status}"},
{"field":"remark1","label":"对方备注","type":"string","value":"{remark1}"},
{"field":"remark2","label":"我方备注","type":"string","value":"{remark2}"}
]
}通过上述配置,我们能够将聚水潭系统中的字段映射到 MySQL 中相应的字段,并进行必要的数据清洗和转换。例如,将 is_main 字段根据其值进行条件转换,以适应 MySQL 的布尔型字段。
数据写入 MySQL
高吞吐量的数据写入能力
轻易云数据集成平台支持高吞吐量的数据写入能力,使得大量数据能够快速被集成到 MySQL 系统中。以下是主要的 SQL 执行语句配置:
{
"field":"main_sql",
"label":"主语句",
"type":"string",
"describe":"SQL首次执行的语句,将会返回:lastInsertId",
// SQL 插入语句
// REPLACE INTO wms_partner (name, co_id, wms_co_id, is_main, status, remark1, remark2) VALUES (:name, :co_id, :wms_co_id, :is_main, :status, :remark1, :remark2);
}通过使用 REPLACE INTO 语句,可以确保在插入新记录时,如果存在相同主键,则替换旧记录。这种方式能够有效地避免重复记录的问题。
数据质量监控与异常处理
实现实时监控与日志记录
在整个 ETL 转换过程中,轻易云提供了集中监控和告警系统,实时跟踪数据集成任务的状态和性能。如果在写入过程中发生异常,可以及时捕获并记录日志,以便后续分析和处理。
错误重试机制
对于可能出现的数据写入失败情况,可以实现错误重试机制。例如,当网络波动或数据库连接超时时,通过重试策略确保最终的数据一致性和完整性。
总结
通过上述技术方案,我们可以高效地将聚水潭系统中的仓库信息数据转换并写入到 MySQL 平台。在这个过程中,自定义的数据转换逻辑、实时监控与日志记录、高吞吐量的数据写入能力,以及错误重试机制等特性共同保障了整个 ETL 转换过程的稳定性和可靠性。